MIT6.824 分布式系统 MapReduce
MapReduce 模型
MapReduce 是一种编程模型,用于大规模数据集(大于1TB)的并行运算。
MapReduce 类似函数式语言中的 map 和 reduce ,计算接受一组键值对,并产生一组新的键值对。
- Map 接受输入的键值对,并产生新的中间键值对,这些中间产物是分散存储的。这些中间键值对被根据键进行 group 操作,然后传给 Reduce 进一步进行操作
- Reduce 接受中间产物一个键和多个与它对应的值。Reduce 将会把值进行合并,通常合并后的大小会是 1 或者 0。
如果用 haskell 的类型签名表示,大概会是这个样子
map :: (InputKey, InputValue) -> [(IntermediateKey, IntermediateValue)]reduce :: (IntermediateKey, [IntermediateValue]) -> [Value]执行过程
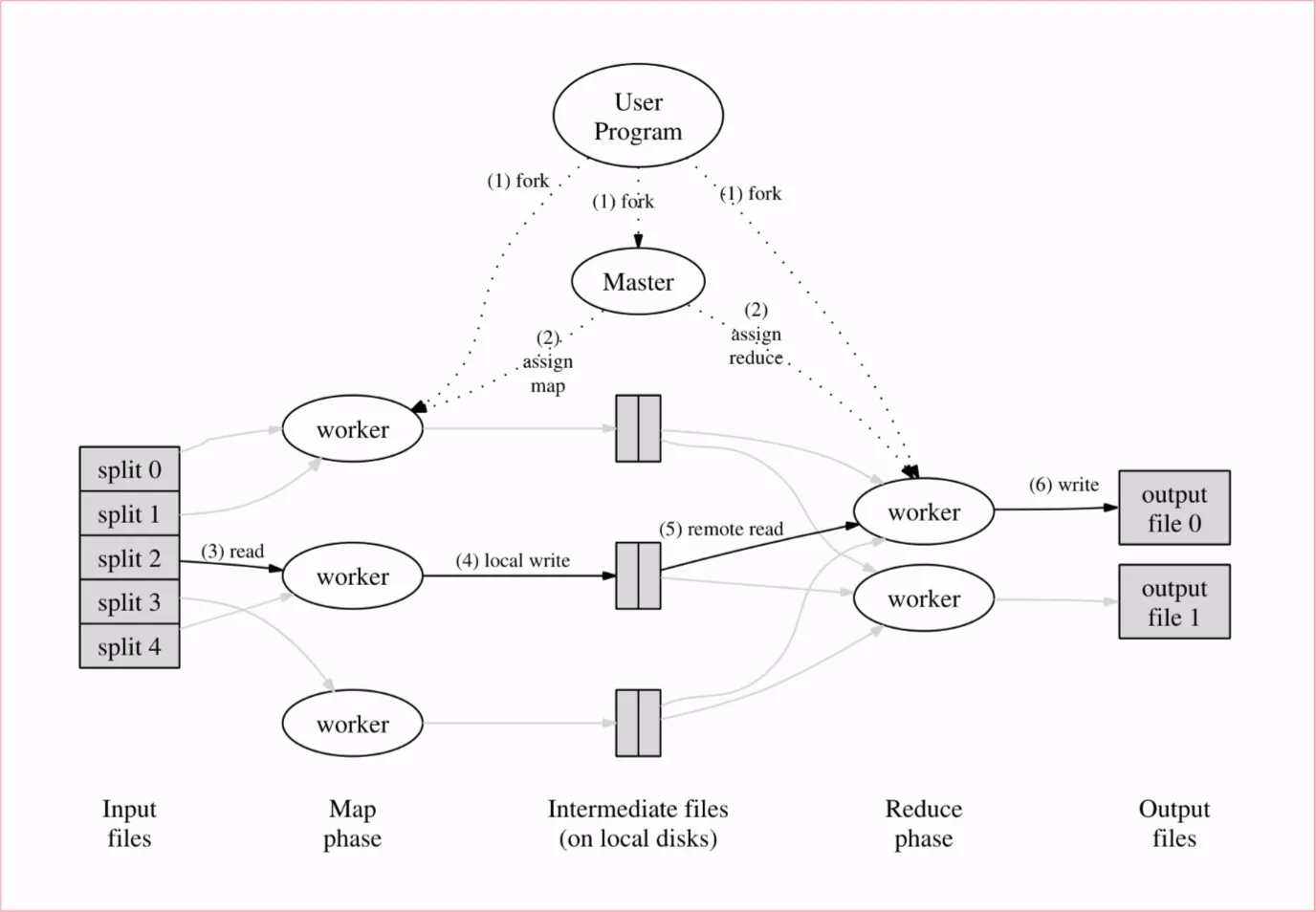
该计算模型由多个worker组成,其中一个 worker 会作为 Master 运行协调器
- 用户程序将输入数据分割为 份,并在 worker 上启动程序的副本
- 将其中一个 worker 作为 Master,其他的 worker 负责执行 map 和 reduce 操作。全过程需要指定 个 map 任务和 个 reduce 任务
- 执行 map 的 worker 从读入输入数据的部分文件,并将结果保留在内存中
- worker 周期性将内存中的数据写到本地硬盘中,并将其分为 组。输出数据的位置将被传回 Master,Master将数据的位置转发给另一个空闲的 worker(指派 reduce 任务)
- 执行 reduce 任务的 worker 通过 RPC从执行 map 的 worker 的本地硬盘中读入数据到缓冲区中。当读入结束后,worker 会对键进行排序,具有相同 key 的将会被分为一组。这个过程有可能要进行外排序
- 执行 reduce 任务的 worker 将遍历排序后的中间数据,对于每个唯一的 key,worker 将会对其执行对应的 reduce 操作,操作结果将会被存储在最终文件中。当操作结束后,更改文件名为最终文件名
- 当所有的 map 和 reduce 任务结束后,重新唤醒用户程序
用户可以选择的合并份最终结果数据,但大部分不需要合并。
要保证map 操作和 reduce 操作是 pure,对本地硬盘的操作是原子化的,以便在错误中恢复
错误处理
worker 故障
master 周期性的检查每个 worker。如果在一段时间中 worker 没有回应,那么 master 将其标记为“故障”。这时 map 或者 reduce 任务和 worker 都会被重置为初始的空闲状态
因为故障 worker 的本地硬盘无法访问,所以即使 map 任务已经完成,这个任务也要重新执行。但如果 reduce 任务所在的 worker 故障则不需要
master 故障
- 方式一: master 周期性的设置检查点,如果 master 故障,新的 master 将从检查点恢复
- 方式二:用户程序检查 master,发现故障时整个重新执行
一般来说 master 的故障比较稀少,所以方式二更常用
Master 数据结构
Master包含多种数据结构。对于每个 Map 和 Reduce 任务保存它们的状态(空闲,进行中或者是完成)。对于不是空闲状态的任务,保存其执行的 Worker。
对于每个完成的 Map 任务,Master 会保持个中间产物的位置和大小。更新这些信息将会表明 map task 被完成。这些信息也会被增量的推送到正在进行中的 Reduce 任务
备份任务
任务执行的总时间受长尾效应的影响,故在任务接近结束时,Master 将仍未完成的任务重复分给第多个其他空闲 Worker,执行同一个任务的 Worker 有一个完成任务,就看作这个任务被完成,不需要在意落后者的执行进度。
Lab 结构
这一节的 Lab 在 6.824 Lab 1: MapReduce
目标为实现一个由两个程序组成的分布式 MapReduce,这两个程序分别是 Coordinator 和 Worker。模型中只会有一个 Coordinator,但会有多个 Worker 并行执行。Worker 将会通过 RPC 与 Coordinator 进行通信,获取输入信息,执行任务并将结果输出到一个或多个文件中。如果在规定的时间内(在Lab 中规定为 10 秒)Worker没有完成任务,Coordinator 应当通另一个 Worker 启动相同的任务
在开始给出的代码中,coordinator 和 worker 将分别用 main/mrcoordinator.go 和 main/mrworker.go 中其中,不应该修改这两个文件。MapReduce 应该从 mr/coordinator.go 、mr/worker.go 和 mr/rpc.go 中实现
如果需要运行统计字数的 MapReduce 任务,首先应该编译 word-count 的插件
$ go build -race -buildmode=plugin ../mrapps/wc.go在 main 目录中运行 coordinator
$ rm mr-out*$ go run -race mrcoordinator.go pg-*.txtpg-*.txt 参数作为指明 mrcoordinator.go 的输入文件,每个文件对应了一个 split,应当作为单独的一个 Map 任务执行
在其他窗口中运行 worker:
$ go run -race mrworker.go wc.so当 workers 和 coordinator 执行完成后,检查 mr-out-*的输出,它们应该和串行执行的文件内容一致。
$ cat mr-out-* | sort | more项目中还提供了测试脚本 main/test-mr.sh,这个测试简本会检查 MapReduce 实现的结果的正确性和 worker 故障的情况
规则
- Map 阶段应当把 intermediate keys 分到桶中以备
nReduce个reduce个任务。nReduce是main/mrcoordinator.go向MakeCoordinator()传递的参数。每个 mapper 需要创建nReduce个中间文件 - 在 worker 实现时,第 个 Reduce 的输出应该到
mr-out-X中 mr-out-X文件应该将 Reduce 函数的每个输出保存在一行中。每一行以%v %v的方式输出。可以参考main/mrsequential.go文件。- 可以修改
mr/worker.go、mr/coordinator.go和mr/rpc.go文件,可以临时修改其他文件来进行测试,但是最终提交时请保证代码在文件的原始版本可以正常执行 - worker 应该将 Map 输出的临时文件存放在当前目录下,Reduce 之后可以直接收入
- 在 MapReduce 工作完全结束后,
mr/coordinator.go中的Done()方法应该返回 true 给main/mrcoordinator.go - 当任务彻底完成后,worker进程应当退出,比较简单的实现方式为使用
call()函数的返回值:如果 worker 与 coordinator 通信失败,就可以假定 coordinator 因为工作完成而退出了,所以 worker 进程也可以终止。
提示
-
Guidance page 有一些关于开发和调试的建议
-
开始任务的方式之一是修改
mr/worker.go的Worker()来向 coordinator 发送 RPC 来请求任务。修改 coordinator 回应未开始的map任务的文件名。然后修改 worker 来读取文件并启动 Map 函数 -
应用的
Map和Reduce函数由 Go 的 plugin 包在运行时动态加载 -
当修改了
mr/目录下的文件后,记得用类似go build -race -buildmode=pugin ../mrapps/wc.go的方式重新编译 -
这个 lab 依赖共享文件系统,这直接导致所有的 worker 必须运行在同一台主机上。如果要 worker 运行在不同的主机上,需要像 GFS 这样的全局分布式文件系统
-
一个较为合理的中间文件的命名方式为
mr-X-Y,其中X表示 Map 任务号,Y表示 Reduce 任务号 -
Worker 的 map 任务需要一种方式来在文件中保存中间产生的键值对,这种方式需要能被 reduce 任务重新正确的读取。一种可行的方式是使用
encoding/json包。向一个文件中写出键值对:enc := json.NewEncoder(file)for _, kv := ... {err := enc.Encode(&kv)将数据读回
dec := json.NewDecoder(file)for {var kv KeyValueif err:= dec.Decode(&kv); err != nil {break}kva = append(kva, kv)} -
worker 的 map 部分可以使用在
worker.go中定义的ihash(key)函数来根据给出的键选择对应的 reduce 任务 -
可以参考
mrsequential.go中的一些读取 Map 输入文件、对中间键值对进行排序、存储Reduce输出的代码 -
Coordinator 作为 RPC 服务器是并发的,别忘了锁数据
-
使用
go build -race和go run -race来运行 Go 的冲突检测器 -
Workers 有时需要进行等待,比如当 reduces 直到最后一个 map 任务结束后才能启动。一种可行解为 worker 周期性向 coordinator 进行询问,并在每次询问后使用
time.Sleep()进行等待。或者说在相应的 RPC handler 中使用循环+time.Sleep()+sync.Cond进行等待。Go语言对每个 RPC 的 handler 都启动一个线程,所以一个 handler 的等待不会影响其他 RPC。 -
Coordinator 可能无法可靠的区分崩溃的 worker,正在运行但因某种原因停滞的 worker 和运行速度太慢而无用的 worker。Coordinator 所能做的最好的事情是等待一段时间,然后放弃这个 worker 并为此任务指定一个新 worker。对于这个 lab,coordinator 应该等待 10 秒钟,如果10秒钟 worker 未完成,则应该假定 worker 崩溃
-
如果选择实现备份任务,评测机在测试代码在工作线程执行任务而不崩溃时不会安排无关的任务。 所以备份任务只能在相对较长的时间(例如 10 秒)后安排。
-
为了测试错误恢复,可以使用
mrapps/crash.go应用插件。它会随机性的退出 -
为了确保在发生崩溃时部分写入的错误文件没有被使用,MapReduce 论文提到了使用临时文件并在完全写入后自动重命名的技巧。 可以使用
ioutil.TempFile创建临时文件,并使用os.Rename以原子方式重命名它。 -
Go RPC 仅发送结构体中以大写字母开头的字段
-
当通过指针来向 RPC 系统回复信息时,
*reply所指向的对象应该是 Zero Allocation, RPC 调用的代码应该是这样:reply := SomeType()call(..., &reply)在调用之前没有设置任何字段。如果不满足这个要求,则当您将回复字段预先初始化为该数据类型的非默认值,并且执行 RPC 的服务器将该回复字段设置为默认值时,就会出现问题; 您将观察到写入似乎没有生效,并且在调用方,非默认值仍然存在。
设计思路
结构
通过阅读已有的代码,项目中已经存在 RPC 框架和借助 go plugin 加载 MapReduce 用户代码的框架。
- Lab 的核心是 map 和 reduce 任务,这个任务必须记录状态以备安排调度。状态应该有
IDLE,RUNNING,COMPETE三种。失败的任务可以被重置为IDLE状态来再次执行。 - 任务需要有个编号
id用来标记任务的输出文件名和调试信息 - 因为 reduce 任务的数据需要依赖 map 任务的结果,所有任务必须记录他们的输入数据和返回数据。
- 为了区分任务是否失败,需要记录任务启动的时间来判断当前任务执行的时间
- 为了方便调试,可能需要记录 Worker 的身份
全过程的数据变化如下
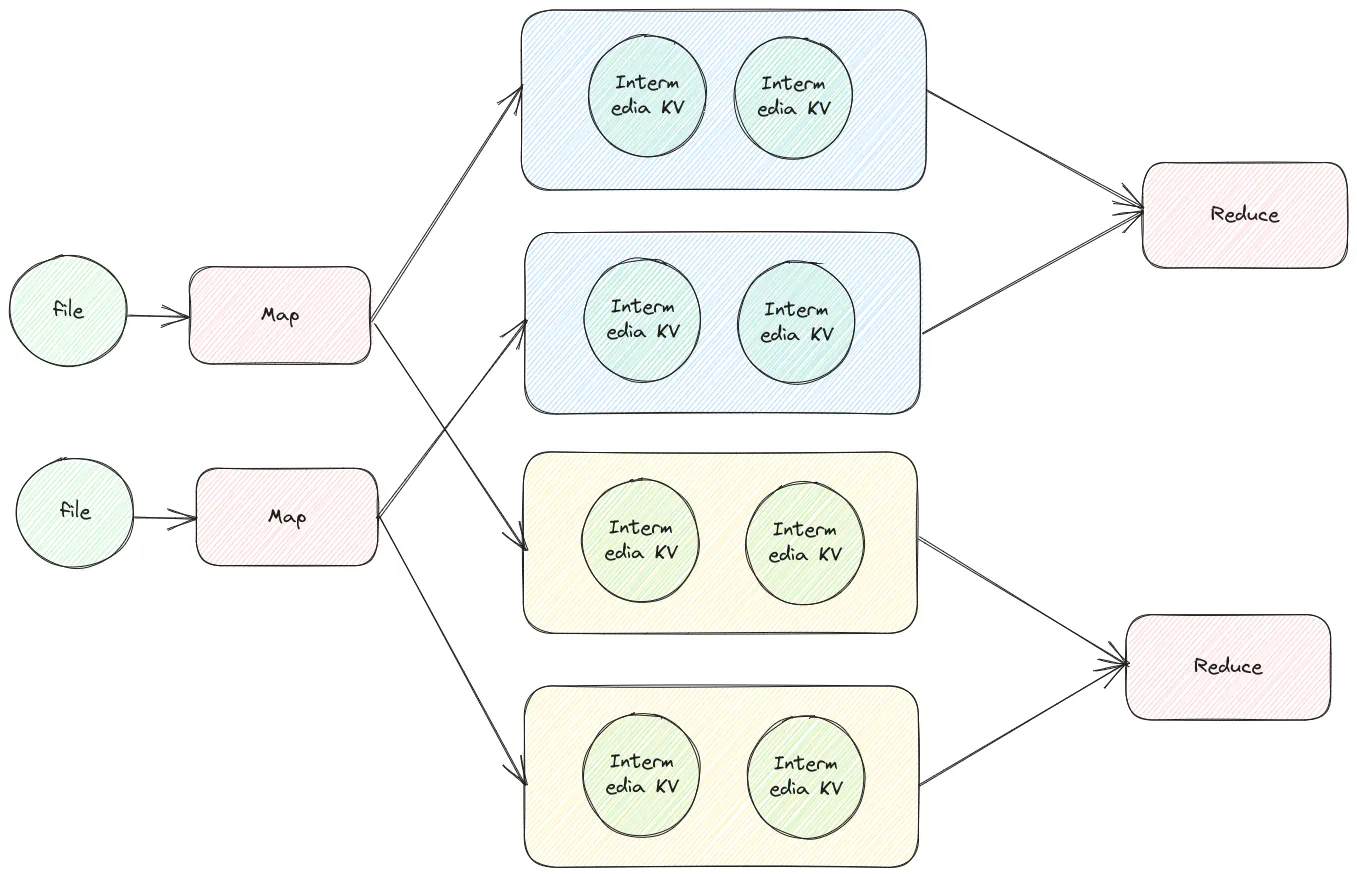
在一个 map 的 worker 中,不同 key 的 hash % nReduce 相同的会被分到一组,并存放在一个文件中。另一个 map 中同理。不同 worker 的相同 hash % nReduce 的值会被送到同一个 reduce 任务中。
也就是说 map 任务接受一个文件,返回 个文件。reduce 任务接受 个文件,返回一个文件。
根据以上信息,我们可以总结出 Map 和 Reduce 两种任务的类型
type TaskStatus int
const ( TaskStatus_Idle TaskStatus = 0 TaskStatus_Running TaskStatus = 1 TaskStatus_Completed TaskStatus = 2)
type WorkerIdent string
type MapTask struct { id int status TaskStatus inputFilename string
startTime int64 worker WorkerIdent}
type ReduceTask struct { id int status TaskStatus inputFilename []string
startTime int64 worker WorkerIdent resultHandle string}再来设计 Coordinator 的类型。
- 因为 Coordinator 需要记录所有的任务,所以肯定需要
[]MapTask和[]ReduceTask - 记录任务完成的数量:如果 map 任务完成的数量等于 map 任务的数量,那么后续只需要考虑 reduce 任务的分配,而 reduce 任务完成后即可退出
- 这是并行服务器,记得加锁
type Coordinator struct { mapTasks []MapTask reduceTasks []ReduceTask
completedMapTask int completedReduceTask int mu sync.Mutex}那么以上就是 Coordinator 内部所需要存储的所有状态。Coordinator 启动时应该初始化所有的 Map 任务,并在 Worker 启动后向其分配任务
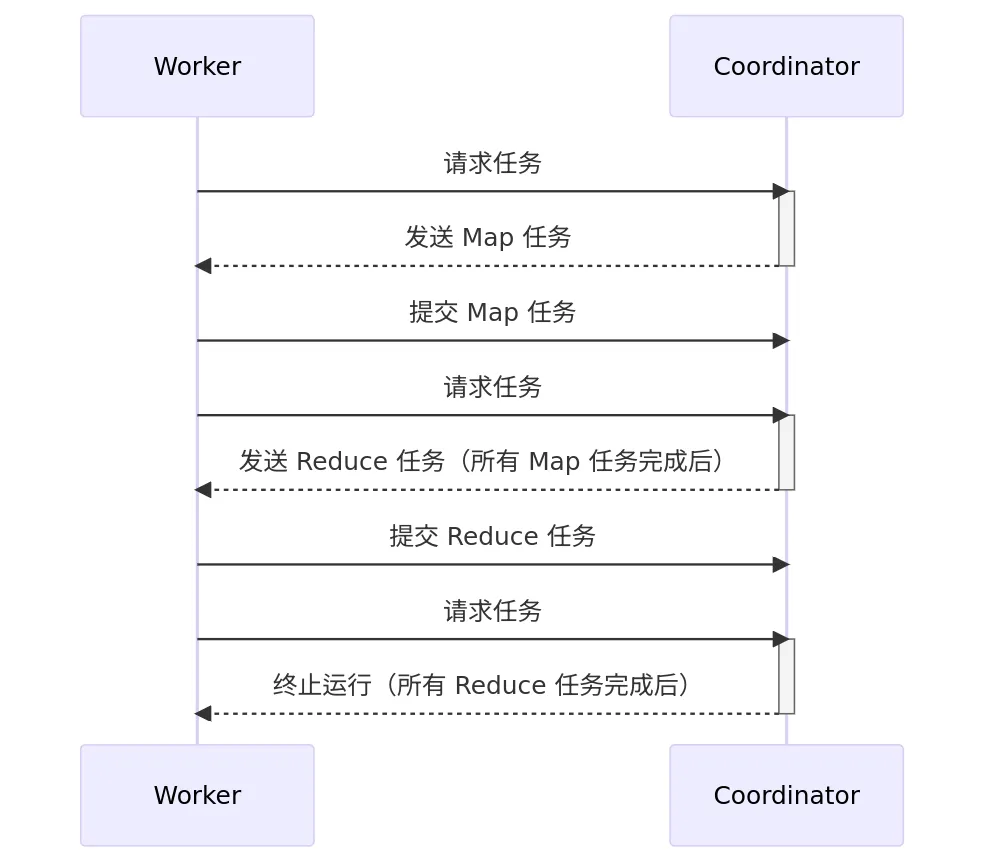
const ( TaskTy_Map = 1 TaskTy_Reduce = 2 TaskTy_None = 3)
type GainTaskArgs struct { WorkName string}type GainTaskReply struct { TaskId int TaskTy TaskType ReduceNumber int InputFileHandle []string}type SubmitMapTaskArgs struct { TaskId int WorkerName WorkerIdent ResultFileHandle []string}type SubmitMapTaskReply struct { Accept bool}type SubmitReduceTaskArgs struct { TaskId int WorkerName WorkerIdent ResultFile string}type SubmitReduceTaskReply struct { Accept bool}检查失败任务
Coordinator 应该检查 Worker 是否失败(故障)。这里使用判断10s 内任务是否结束,如果任务未结束,则表示任务可能停滞(故障),应该将任务标记为 IEDL 状态。
由于 10s 的判断是实时的,不能在收到 Worker 信息的时候判断,否则如果所有的 Worker 都滞后时 Coordinator 也会滞后。这里采用开启一个线程每隔一段时间对所有的 Task 进行一次检查,并顺手更新所有任务的完成状态。
记得在检查时加锁
备份任务
这实际上是一个坑点。由于测试数据中会检测 map 任务的执行数量,使用 Backup Task 可能会导致任务数量执行过多。在该 Lab 中应该按照要求,当任务超过 10s 后才应该启动备份任务,而非立刻执行。
完整代码
包含 Backup Task,不含挑战
coordinator.go
package mr
import ( "log" "sync" "time")import "net"import "os"import "net/rpc"import "net/http"
type TaskStatus int
const ( TaskStatus_Idle TaskStatus = 0 TaskStatus_Running TaskStatus = 1 TaskStatus_Completed TaskStatus = 2)
type WorkerIdent string
type GroupedIntermediaKV []KeyValue
type MapTask struct { id int inputFileName string status TaskStatus
startTime int64 worker WorkerIdent resultHandle []GroupedIntermediaKV}
type ReduceTask struct { id int status TaskStatus inputFileName []string
startTime int64 worker WorkerIdent resultHandle string}
type Coordinator struct { mapTasks []MapTask reduceTasks []ReduceTask
completedMapTask int completedReduceTask int mu sync.Mutex}
// start a thread that listens for RPCs from worker.gofunc (c *Coordinator) server() { rpc.Register(c) rpc.HandleHTTP() //l, e := net.Listen("tcp", ":1234") sockname := coordinatorSock() os.Remove(sockname) l, e := net.Listen("unix", sockname) if e != nil { log.Fatal("listen error:", e) } go http.Serve(l, nil)}
func (c *Coordinator) maintainTask() { c.mu.Lock() currentTime := time.Now().Unix() log.Printf("Check tasks on %d", currentTime) completedMap := 0 completedReduce := 0
defer c.mu.Unlock()
for i := 0; i < len(c.mapTasks); i++ { if c.mapTasks[i].status == TaskStatus_Running && currentTime-c.mapTasks[i].startTime > 10 { // mark as failure log.Printf("Mark map task %d fail", c.mapTasks[i].id, c.mapTasks[i].worker) c.mapTasks[i].startTime = 0 c.mapTasks[i].status = TaskStatus_Idle } else if c.mapTasks[i].status == TaskStatus_Completed { completedMap++ } }
for i := 0; i < len(c.reduceTasks); i++ { if c.reduceTasks[i].status == TaskStatus_Running && currentTime-c.reduceTasks[i].startTime > 10 { // mark as failure log.Printf("Mark reduce task%d fail", c.reduceTasks[i].id, c.reduceTasks[i].worker) c.reduceTasks[i].startTime = 0 c.reduceTasks[i].status = TaskStatus_Idle } else if c.reduceTasks[i].status == TaskStatus_Completed { completedReduce++ } }
if completedMap != c.completedMapTask { c.completedMapTask = completedMap } if completedReduce != c.completedReduceTask { c.completedReduceTask = completedReduce }}
func (c *Coordinator) GainTask(args *GainTaskArgs, reply *GainTaskReply) error { c.maintainTask() c.mu.Lock() defer c.mu.Unlock()
reply.ReduceNumber = len(c.reduceTasks) reply.TaskTy = TaskTy_None
distributeMapTask := func(task *MapTask) { log.Printf("Distribute map task %d to worker %s", task.id, args.WorkName) reply.TaskTy = TaskTy_Map reply.TaskId = task.id reply.InputFileHandle = []string{task.inputFileName}
task.status = TaskStatus_Running task.startTime = time.Now().Unix() task.worker = WorkerIdent(args.WorkName) } distributeReduceTask := func(task *ReduceTask) { log.Printf("Distribute reduce task %d to worker %s", task.id, args.WorkName) reply.TaskTy = TaskTy_Reduce reply.TaskId = task.id reply.InputFileHandle = task.inputFileName
task.status = TaskStatus_Running task.startTime = time.Now().Unix() task.worker = WorkerIdent(args.WorkName) }
if c.completedMapTask < len(c.mapTasks) { // distribute map task for i := range c.mapTasks { var task = &c.mapTasks[i] if task.status == TaskStatus_Idle { distributeMapTask(task) return nil } } } for c.completedMapTask < len(c.mapTasks) { // distribute map task currentTime := time.Now().Unix() for i := range c.mapTasks { var task = &c.mapTasks[i] if task.status != TaskStatus_Completed && currentTime-task.startTime > 10 { distributeMapTask(task) return nil } } c.mu.Unlock() time.Sleep(1 * time.Second) c.mu.Lock() }
if c.completedReduceTask < len(c.reduceTasks) { // distribute reduce task for i := range c.reduceTasks { var task = &c.reduceTasks[i] if task.status == TaskStatus_Idle { distributeReduceTask(task) return nil } } } for c.completedReduceTask < len(c.reduceTasks) { // distribute reduce task currentTime := time.Now().Unix() for i := range c.reduceTasks { var task = &c.reduceTasks[i] if task.status != TaskStatus_Completed && currentTime-task.startTime > 10 { distributeReduceTask(task) return nil } } c.mu.Unlock() time.Sleep(1 * time.Second) c.mu.Lock() }
return nil}
func (c *Coordinator) SubmitMapTask(args *SubmitMapTaskArgs, reply *SubmitMapTaskReply) error { c.mu.Lock() defer c.mu.Unlock() if c.mapTasks[args.TaskId].status != TaskStatus_Completed { log.Printf("Accept map task %d from worker %v", args.TaskId, args.WorkerName) reply.Accept = true c.mapTasks[args.TaskId].status = TaskStatus_Completed for rid, filename := range args.ResultFileHandle { c.reduceTasks[rid].inputFileName = append(c.reduceTasks[rid].inputFileName, filename) } } else { log.Printf("Refuse map task %d from worker %v", args.TaskId, args.WorkerName) reply.Accept = false }
return nil}
func (c *Coordinator) SubmitReduceTask(args *SubmitReduceTaskArgs, reply *SubmitReduceTaskReply) error { c.mu.Lock() defer c.mu.Unlock() if c.reduceTasks[args.TaskId].status != TaskStatus_Completed { log.Printf("Accept reduce task %d from worker %v", args.TaskId, args.WorkerName) reply.Accept = true c.reduceTasks[args.TaskId].status = TaskStatus_Completed c.reduceTasks[args.TaskId].resultHandle = args.ResultFile } else { log.Printf("Refuse reduce task %d from worker %v", args.TaskId, args.WorkerName) reply.Accept = false } return nil}
// main/mrcoordinator.go calls Done() periodically to find out// if the entire job has finished.func (c *Coordinator) Done() bool { c.mu.Lock() defer c.mu.Unlock() return c.completedReduceTask == len(c.reduceTasks)}
// create a Coordinator.// main/mrcoordinator.go calls this function.// nReduce is the number of reduce tasks to use.func MakeCoordinator(files []string, nReduce int) *Coordinator { c := Coordinator{}
c.reduceTasks = make([]ReduceTask, nReduce) for i := 0; i < nReduce; i++ { t := &c.reduceTasks[i] t.id = i t.status = TaskStatus_Idle }
for id, splitFile := range files { c.mapTasks = append(c.mapTasks, MapTask{ id: id, status: TaskStatus_Idle, inputFileName: splitFile, }) log.Printf("Schedule map task %d from %s", id, splitFile) } go func() { for { c.maintainTask() time.Sleep(time.Second) } }()
log.Println("Coordinator tasks init finish") c.server() return &c}worker.go
package mr
import ( "encoding/json" "fmt" "io" "math/rand" "os" "os/exec" "sort" "time")import "log"import "net/rpc"import "hash/fnv"
// Map functions return a slice of KeyValue.type KeyValue struct { Key string Value string}
// use ihash(key) % NReduce to choose the reduce// task number for each KeyValue emitted by Map.func ihash(key string) int { h := fnv.New32a() h.Write([]byte(key)) return int(h.Sum32() & 0x7fffffff)}
// for sorting by key.type ByKey []KeyValue
func (a ByKey) Len() int { return len(a) }func (a ByKey) Swap(i, j int) { a[i], a[j] = a[j], a[i] }func (a ByKey) Less(i, j int) bool { return a[i].Key < a[j].Key }
func ExecuteMap(mapf func(string, string) []KeyValue, taskId int, inputFileHandle string, nReduce int, workerName WorkerIdent) { log.Printf("Start map task %d", taskId)
file, err := os.Open(inputFileHandle) if err != nil { log.Fatal(err) } content, err := io.ReadAll(file) if err != nil { log.Fatal(err) } kv := mapf(inputFileHandle, string(content))
kva := make(map[int][]KeyValue) for _, p := range kv { rid := ihash(p.Key) % nReduce kva[rid] = append(kva[rid], p) }
params := SubmitMapTaskArgs{TaskId: taskId, ResultFileHandle: make([]string, nReduce), WorkerName: workerName} reply := SubmitMapTaskReply{}
for rid, intermedia := range kva { filename := fmt.Sprintf("mr-%d-%d", taskId, rid) params.ResultFileHandle[rid] = filename
file, err := os.Create(filename) defer file.Close() if err != nil { log.Fatal(err) } enc := json.NewEncoder(file) for _, kv := range intermedia { err := enc.Encode(&kv) if err != nil { log.Fatal(err) } } }
if !call("Coordinator.SubmitMapTask", ¶ms, &reply) { log.Fatal("Coordinator is down?") } if reply.Accept { log.Printf("Map task%d completed", taskId) } else { log.Printf("Map task%d unacceptable", taskId) }}
func ExecuteReduce(reducef func(string, []string) string, taskId int, inputFileHandles []string, workerName WorkerIdent) { log.Printf("Start reduce task %d", taskId)
kva := make([]KeyValue, 0) for _, handle := range inputFileHandles { if handle == "" { continue }
file, err := os.Open(handle) if err != nil { log.Fatal(err) } dec := json.NewDecoder(file) for { var kv KeyValue if err := dec.Decode(&kv); err != nil { break } kva = append(kva, kv) } }
sort.Sort(ByKey(kva))
oname := fmt.Sprintf("mr-out-%d", taskId) ofile, _ := os.CreateTemp("", oname+"-*")
i := 0 for i < len(kva) { j := i + 1 for j < len(kva) && kva[j].Key == kva[i].Key { j++ } values := []string{} for k := i; k < j; k++ { values = append(values, kva[k].Value) } output := reducef(kva[i].Key, values)
// this is the correct format for each line of Reduce output. fmt.Fprintf(ofile, "%v %v\n", kva[i].Key, output) i = j }
err := os.Rename(ofile.Name(), oname) if err != nil { log.Fatal(err) } params := SubmitReduceTaskArgs{ TaskId: taskId, WorkerName: workerName, ResultFile: oname, } reply := SubmitReduceTaskReply{} if !call("Coordinator.SubmitReduceTask", ¶ms, &reply) { log.Fatal("Coordinator is down?") } if reply.Accept { log.Printf("Reduce task%d completed", taskId) } else { log.Printf("Reduce task%d unacceptable", taskId) }}
// main/mrworker.go calls this function.func Worker(mapf func(string, string) []KeyValue, reducef func(string, []string) string) { rand.Seed(time.Now().UnixNano()) workerName, err := exec.Command("uuidgen").Output() if err != nil { log.Fatal(err) } log.Printf("Worker name: %s\n", workerName)
for { taskReply := GainTaskReply{} call("Coordinator.GainTask", GainTaskArgs{WorkName: string(workerName)}, &taskReply)
if taskReply.TaskTy == TaskTy_Map { ExecuteMap(mapf, taskReply.TaskId, taskReply.InputFileHandle[0], taskReply.ReduceNumber, WorkerIdent(workerName)) } else if taskReply.TaskTy == TaskTy_Reduce { ExecuteReduce(reducef, taskReply.TaskId, taskReply.InputFileHandle, WorkerIdent(workerName)) } else if taskReply.TaskTy == TaskTy_None { log.Printf("Receive exit signal") os.Exit(0) } else { log.Printf("Unrecongized task type %d", taskReply.TaskTy) } }}
// send an RPC request to the coordinator, wait for the response.// usually returns true.// returns false if something goes wrong.func call(rpcname string, args interface{}, reply interface{}) bool { // c, err := rpc.DialHTTP("tcp", "127.0.0.1"+":1234") sockname := coordinatorSock() c, err := rpc.DialHTTP("unix", sockname) if err != nil { log.Fatal("dialing:", err) } defer c.Close()
err = c.Call(rpcname, args, reply) if err == nil { return true }
fmt.Println(err) return false}rpc.go
package mr
//// RPC definitions.//// remember to capitalize all names.//
import "os"import "strconv"
type TaskType int
const ( TaskTy_Map = 1 TaskTy_Reduce = 2 TaskTy_None = 3)
type GainTaskArgs struct { WorkName string}type GainTaskReply struct { TaskId int TaskTy TaskType ReduceNumber int InputFileHandle []string}
type SubmitMapTaskArgs struct { TaskId int WorkerName WorkerIdent ResultFileHandle []string}type SubmitMapTaskReply struct { Accept bool}type SubmitReduceTaskArgs struct { TaskId int WorkerName WorkerIdent ResultFile string}type SubmitReduceTaskReply struct { Accept bool}
// Cook up a unique-ish UNIX-domain socket name// in /var/tmp, for the coordinator.// Can't use the current directory since// Athena AFS doesn't support UNIX-domain sockets.func coordinatorSock() string { s := "/var/tmp/824-mr-" s += strconv.Itoa(os.Getuid()) return s}