The 2020 ICPC Asia Shenyang Regional Programming Contest
The 2020 ICPC Asia Shenyang Regional Programming Contest - Codeforces Gym
B - Whispers of the Old Gods
给出一个正则表达式
pattern和字符串str,要求对字符串中的数字进行尽可能少的插入,删除,替换操作。输出最小的操作次数。
做老题结果发现专业对口这件事
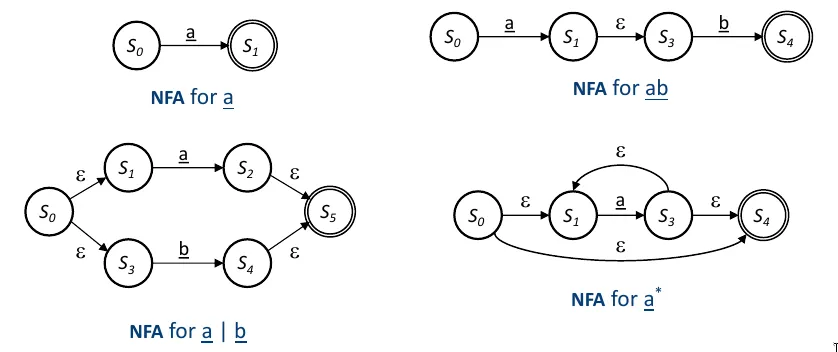
首先根据题目给出的 BNF 写出正则的解析器,然后用 Thompson’s Construction 构造和 pattern 对应的 NFA,
重合 NFA 的起点和 str 的开始符,向后匹配到 NFA 的结束状态即可。当 str 的下一个字符使得 NFA 没有对应转移时,
修改 str 的下一个字符,其实也就相当于一个 01-最短路。
有关 Thompson’s Construction 构造可以参考 Comp412 课件。
- You will be tempted to take shortcuts, such as leaving out some of the transitions
- Do not do it. Memorize these four patterns. They will keep you out of trouble.
如果预先将题目中的 BNF 处理成 LL(1) 类型的文法,可以进一步优化速度,但是训练的时候推了一下,没写。 附当时的推导结果:
D - Journey to Un’Goro
路线中仅包含红蓝两种颜色。输入一个整数,构造一个这样的路线,使的从 出发到达经过的红色数量为奇数的路径的数量最大。
输出满足要求的的最大数量和这些路线。当路线数量大于100个时,仅输出字典序小的前100个。
赛时没做出来
在此介绍一篇神答案 打表+找规律
将 r 设为 ,b 设为 。那么子串中 的数量就是前缀和之差。
考虑什么时候 的数量为奇数:显而易见,当前缀和数组中两个元素的奇偶性不同时,其表示的区间才是奇数。记奇数的个数为 ,偶数的个数为 。那么在这段区间中, 可以选择任何一个前缀和为奇数的元素和一个前缀和为偶数的元素来构成一个其区间为奇数的子区间。显而易见,这种符合条件的子区间的个数应该是 个。
根据高中学的某个忘掉名字的不等式,当 时,取最大值,也就是 和 各取一半的时候。 此时 ,(加一是为了考虑前缀和要留出 = 0 的空间)
根据上述内容,我们一顿爆搜就可以了,当 时直接剪掉即可。
在实际搜索中,我们没必要记录前缀和,只需要维护当前的奇偶状态即可。
F - Kobolds and Catacombs
给你一段序列,将其划分为尽可能多的段,要求每段再重新排序再拼接起来后为非下降序列。
求原序列和排序之后的序列的前缀和,当前缀和元素相等的时候就代表这个位置被分割排序后可以形成非下降序列,此时
时间复杂度 ,瓶颈在排序
能卡着时间过

G - The Witchwood
现在有 个甜点,每个甜点能带来 的愉悦度,Bob 能吃 个甜点。输出 Bob的最大愉悦度是多少。
想必这个就是大名鼎鼎的签到题了
H - The Boomsday Project
某共享单车公司推出了“骑行劵”折扣活动。原本一次骑行需要花费 元,一张折扣卷可以在其有效期限的 天内免费骑行 次。在 天购买的折扣劵将在 天过期。 折扣劵之间可存在覆盖关系,购买新的骑行劵时,旧的骑行劵作废。
现在有 种不同的骑行劵。每种骑行劵需要花费 元购买,在天内享有次免费骑行。一个人可以无限次购买同一种骑行劵。
给出 Aloha 的骑行记录,输出最小花费。
训练时又没做出来
我愿称其为玄学dp。

I - Rise of Shadows
一个钟表,时钟转一圈有 小时,分针转一圈有 分钟。设 。问一天中时钟和分针的夹角小于等于 的时刻有几次。
首先选取时针为参照物,每分钟时针运动角度 ,分针运动角度 其分针相对速度为
在 分钟的时候,时针和分针的夹角为
考虑到可能会有转一圈回来的情况,夹角应该是
另外时针和分针的能形成的角有两个,这两个角互补。我们应该选择小的角,即
也就是求从 这段时间中有多少个 或 成立
在这里,我们很容易发现一种特殊情况,即 时,显然每个时刻都满足题意,答案为
当 时:
对于上式 中,我们可以将 看作 ,将 (H-1) 每个时刻两个指针的变化量。
当存在 时,一定不会有 ,两个部分不会同时存在重叠的答案,所以我们只需要将两部分的答案 加起来即可。
先看第一个式子(其中 表示艾弗森括号)
令 ,当时,由于 ,构成了一个模为 的完全剩余系。 根据其性质可知,也是一个完全剩余系,即它一定取遍了 [0, HM-1] 的每一个数,此时不需要关心那个时刻满足答案,只需要知道范围内有多少 数小于等于 即可。现在在 的范围内总共有 个数满足,答案为
当 时,利用同余性质 ,式子看转化为
也就是相当于把 平均分成 段,每一段的 都模一个 的完全剩余系,, 每一段的答案都是。即第一个式子的所有答案之和为
同理,我们处理第二个式子,得到答案为
吐槽一下我队友在计算过程中把向下取整掉了
不过这位现场百度5分钟内就把完全剩余系学会了,他就是我的神,tql
K - Scholomance Academ
阅读理解题,读懂题意就是小模拟
结果我比有深度学习经验的队友先读懂
以下翻译的术语可能并不正确
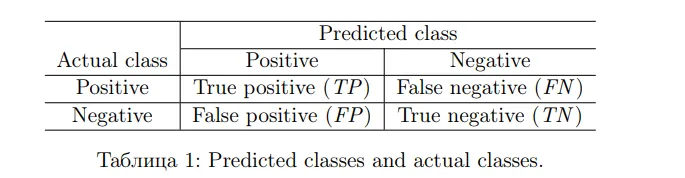
二元分类是一种对已有实例进行分类的算法,分类结果只能是
positive(+)或negative(-)。典型的二元分类算法用一个函数 和一个阈值 进行,当实例的分数 时,实例x被分类为
positive,否则就是negative显然不同的阈值 会产生不同的分类结果。二元分类也存在误判。它可以将实际为
positive的实例判定为negative,这种情况称为false negative;也可以将实际为negative的实例判断为positive,这种情况称为false negative
现在题目给出一个数据集和一个分类器。定义 true positive rate(TPR) 和 false positive rate(FPR) 为以下内容
TPR=\frac{\\#TP}{\\#TP + \\#FN}, FPR=\frac{\\#FP}{\\#TN + \\#FP}
你现在需要评估一个分类器的性能,这个分类器在不同的阈值 下表现的 与 不同。记阈值为 时 TPR 和 FPR 为 和 。那么 area under curve(AUC) 为
式子中被积函数称为 receiver operating characteristic(ROC),意为当 时 的最大值。
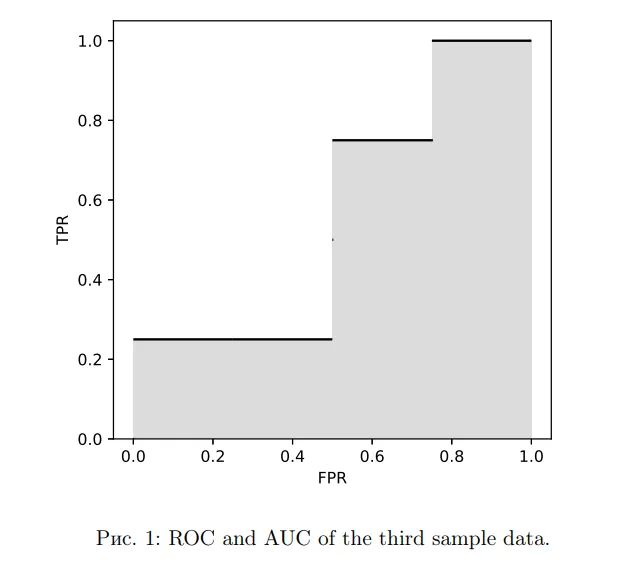
例如现在有三个测试数据,当阈值取值为时,有3个 TP, 2个 FP,2个TN,1个 FN。 因此,此时的 ,。当 变化时,我们能画出 ROC 曲线,并直接计算出 AUC。如图片1。
输入数据
第一行一个整数 (),表示测试集中实例的数量。接下来 行中, 每一行包含一个字符 表示实例的真实类型;一个整数 表示当前实例的分数
输出数据
输出 ,精确到小数点后10位。
我第一反应是扫描线
首先我们需要明确他那个看着吓人的积分函数根本没有任何用处。
我们可以通过枚举 ,每次枚举算出 FPR 和 TPR ,并求出面积。这种方法道理上可行,但实际因为取值范围的问题,并不能用。
退而求其次,因为题目还给了当前实例的分数 ,这个即可表示每次的取值。起始时记 为最大值,此时所有的实例都会被预测为 negative。逐步降低 ,即可得到最后答案,通过预先根据 进行排序,可实现逐步降低。
将 排在 之前可以便于计算。